1.1. Installation¶
The installation procedure can be consolidated to three steps: (a) copy the CSD to your server and restart Cloudera Manager, (b) install the parcel and (c) add a Fast Data service.
Contents
1.1.1. Install the CSD to Cloudera Manager¶
Landoop’s Fast Data CSD is a small jar file that you have to copy to the server that hosts Cloudera Manager. You can find it at your client area. If you are not a customer but interested in a trial run, please contact us here
Important
If you use an older Fast Data CSD, you should remove the old CSD file, copy the new one and restart Cloudera Manager. Please check the upgrade guide for more information.
In a default Cloudera installation, you should place the CSD under
/opt/cloudera/csd. This procedure is highly dependant on your setup and beyond
the scope of this guide. As an example, in our cluster, we would follow the procedure
below:
local $ scp FASTDATA-5.5-release-0.jar cloudera-manager-server:/tmp/
local $ ssh cloudera-manager-server
remote $ sudo cp /tmp/FASTDATA-5.5-release-0.jar /opt/cloudera/csd/
Note
If you are on Cloudera 6.x, please use the file
FASTDATA-5.5-cdh6-release-0.jar.
If you installed Cloudera to a different directory adjust accordingly.
Next you have to either restart Cloudera Manager (recommended by Cloudera) or use the manager’s CSD API to install without restart. The command line to restart CM depends on your Linux distribution of choice. For most modern distributions which rely on systemd, you would run something similar to:
remote $ sudo systemctl restart cloudera-scm-server
This will refresh the Cloudera Manager and enhance it with new capabilities. Existing Hadoop services including HDFS and YARN will not be affected by this restart. If this is the first time installing our CSD, after the restart the manager will indicate that you have to restart the Cloudera Management Service as well. This is too a safe procedure to perform.
Once you complete the steps above, two things will change in your CM (Cloudera Manager); it now includes a Fast Data service type and also has Landoop’s repository for the Kafka Confluent Parcel.
You are ready to proceed to Install the Parcel.
Note
If you prefer the API, you should visit the following two locations. The first asks CM to reload the CSD list and the second to install Landoop’s Fast Data CSD. Cloudera strongly recommends to avoid this method as the CSD may not work properly until CM restart:
http://cloudera.manager.server:7180/cmf/csd/refresh
http://cloudera.manager.server:7180/cmf/csd/install?csdName=FASTDATA-5.5-release-0.jar
1.1.2. Install the Parcel¶
Parcels are software packages for Cloudera Manager. They contain both files and system setup instructions. We provide a range of Kafka parcels for various Linux distributions. The software included in our parcels is our build of Kafka and components, or —optionally— repackaged from Confluent’s Community archives, with instructions for CM as well as some extra components. Various Kafka Connectors are available as extra parcels
The Fast Data CSD installs the appropriate parcel repository for the version you use. You can install our parcel directly from CM’s parcel management page.
Before continuing, if you have installed Cloudera’s Kafka parcel please deactivate it and optionally remove it from hosts. If you installed Kafka from your distribution’s package manager, please remove it using the facilities provided by your package manager.
Our parcel will act as a replacement for these packages and make Kafka’s command line tools available in all your hosts without any special procedure. Kafka best practices recommend that your command line tools should be at the same version as your Kafka brokers. The installation is handled by Cloudera Manager and everything will return to normal should you ever decide to remove the parcel.
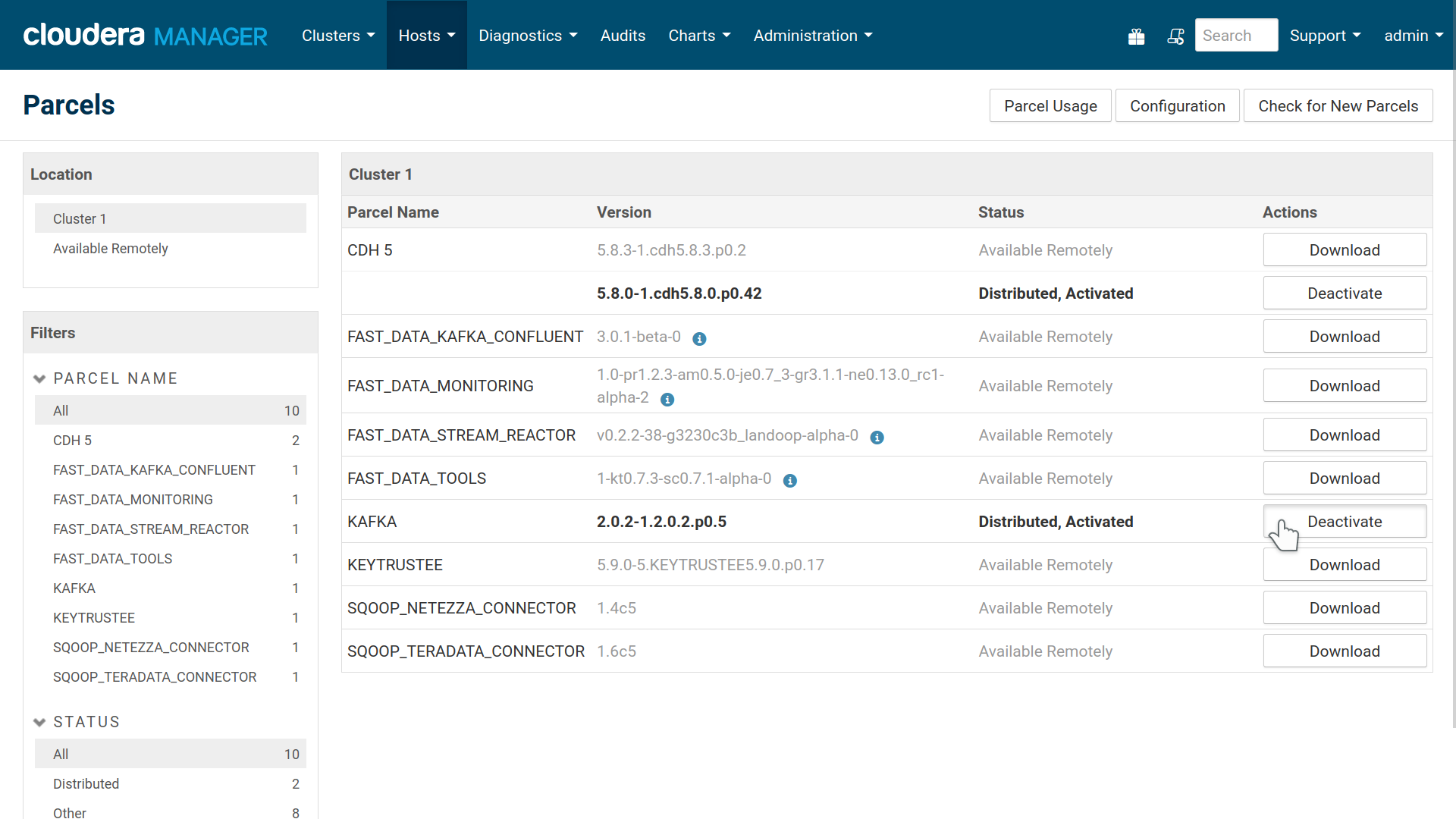
Deactivate existing Kafka installations before installing our parcel. The Fast Data Kafka Confluent parcel provides Kafka support and tooling to your systems.
At the parcel management page of Cloudera Manager you can now proceed to download, distribute and activate the Fast Data Kafka Landoop parcel. The main part of the version (5.5.x) corresponds to Confluent’s releases and the rest to our internal packaging versions. For our Kafka build, the main part of the version (2.5.x) corresponds to Kafka’s releases.
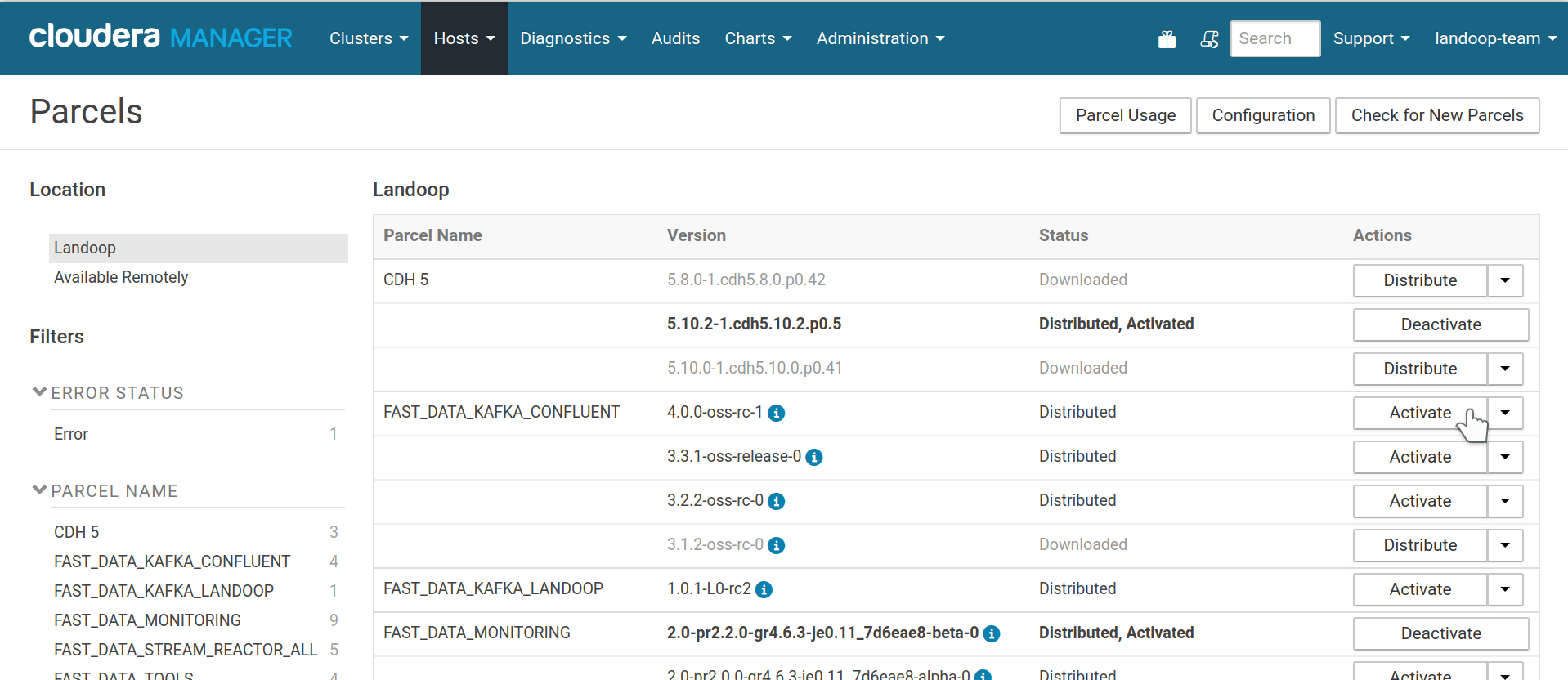
Fast Data kafka Confluent Parcel distributed and activated
Note
If your cluster does not have internet access, Cloudera provides alternative installation paths. Please consult Cloudera’s documentation, you can download our parcels manually and make them available to your cluster through the methods described in this guide.
1.1.3. Add a Fast Data Service¶
A service is a set of roles running on one or more cluster hosts, managed by Cloudera Manager. Our CSD provides the following roles:
- Kafka Broker
- Kafka REST Proxy
- Schema Registry
- Kafka Connect Distributed
- Endpoint Exporter
Note
The mirrormaker role is absent from the current release. We may add it again in a future release with new features and easier setup. The kafka-mirror-maker and connect-mirror-maker utilities are still available, so you can use them from your command line.
You may add as many instances of each Kafka role to a service as your cluster nodes. Brokers, Schema Registry and Connect Distributed are distributed software, which means that instances of the same role in a service work together, providing redundancy (depending on configuration), availability and scaling. Endpoint Exporter is a new role, added in Fast Data 3.3 and you can have at most one instance. It exports the cluster’s configuration, so the Monitoring, Tools and Lenses CSDs can setup automatically.
We do not provide a zookeeper role since CDH comes with its own zookeeper service which works well. In the past it was a common advice to use a separate Zookeeper cluster for Kafka. Newer Kafka versions, such as these we provide, moved the Zookeeper bottleneck (the storage of consumer offsets) into Kafka itself, which is a much better fit for the task. Thus you are able to use a Zookeeper ensemble hosted on the same machines as your brokers. We advise to use the default Zookeeper ensemble of your cluster. If you prefer a separate one, you can add a second Zookeeper service to your cluster and during the Fast Data setup you will be asked to choose which one Kafka should use.
Cloudera manager provides orchestration, configuration, log management and basic monitoring of a service’s roles.
To start with a Fast Data service, inside CM, at your cluster’s menu, select add a service.
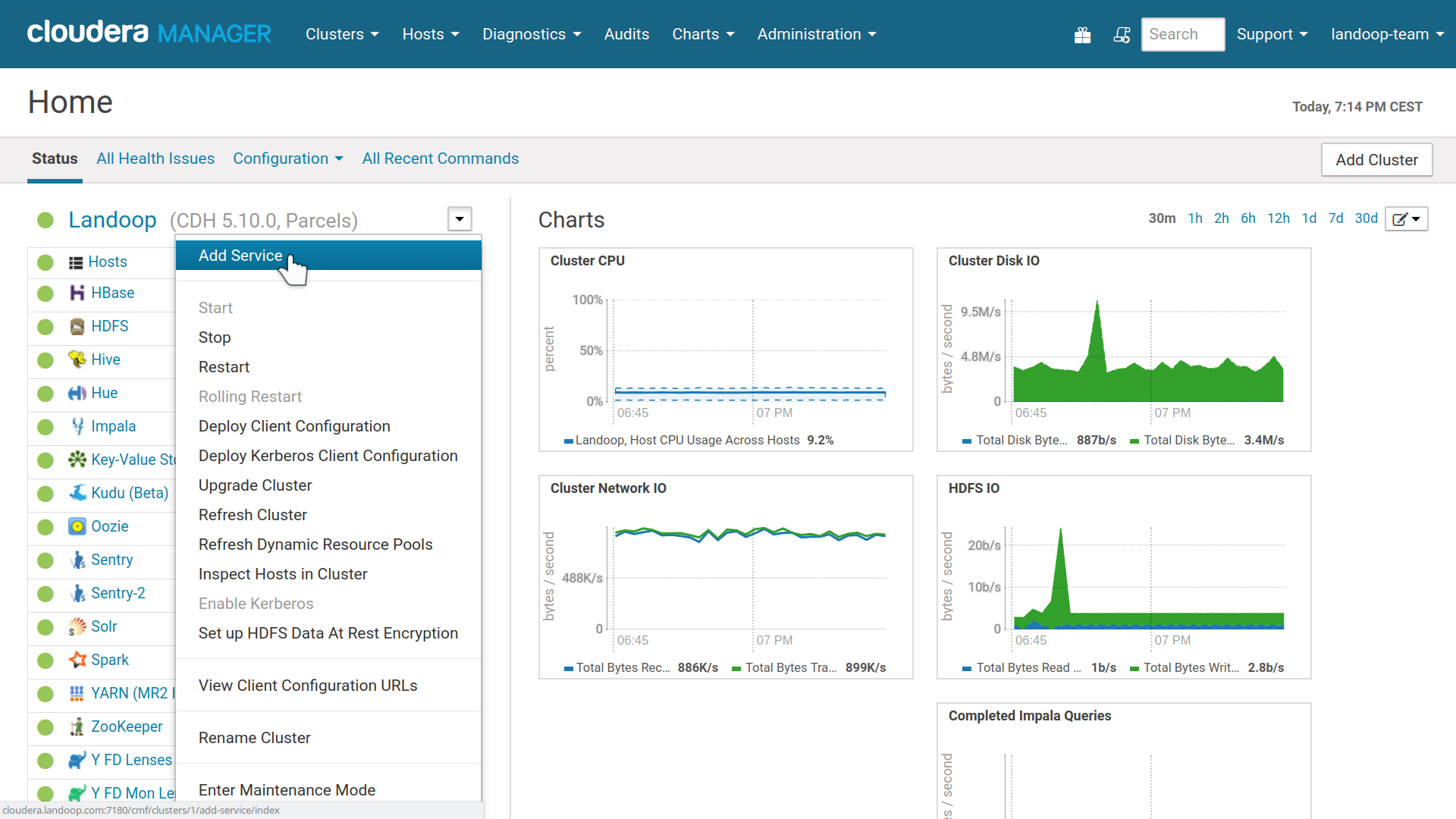
Cloudera Manager, Add a Service
At the first step, choose Fast Data.
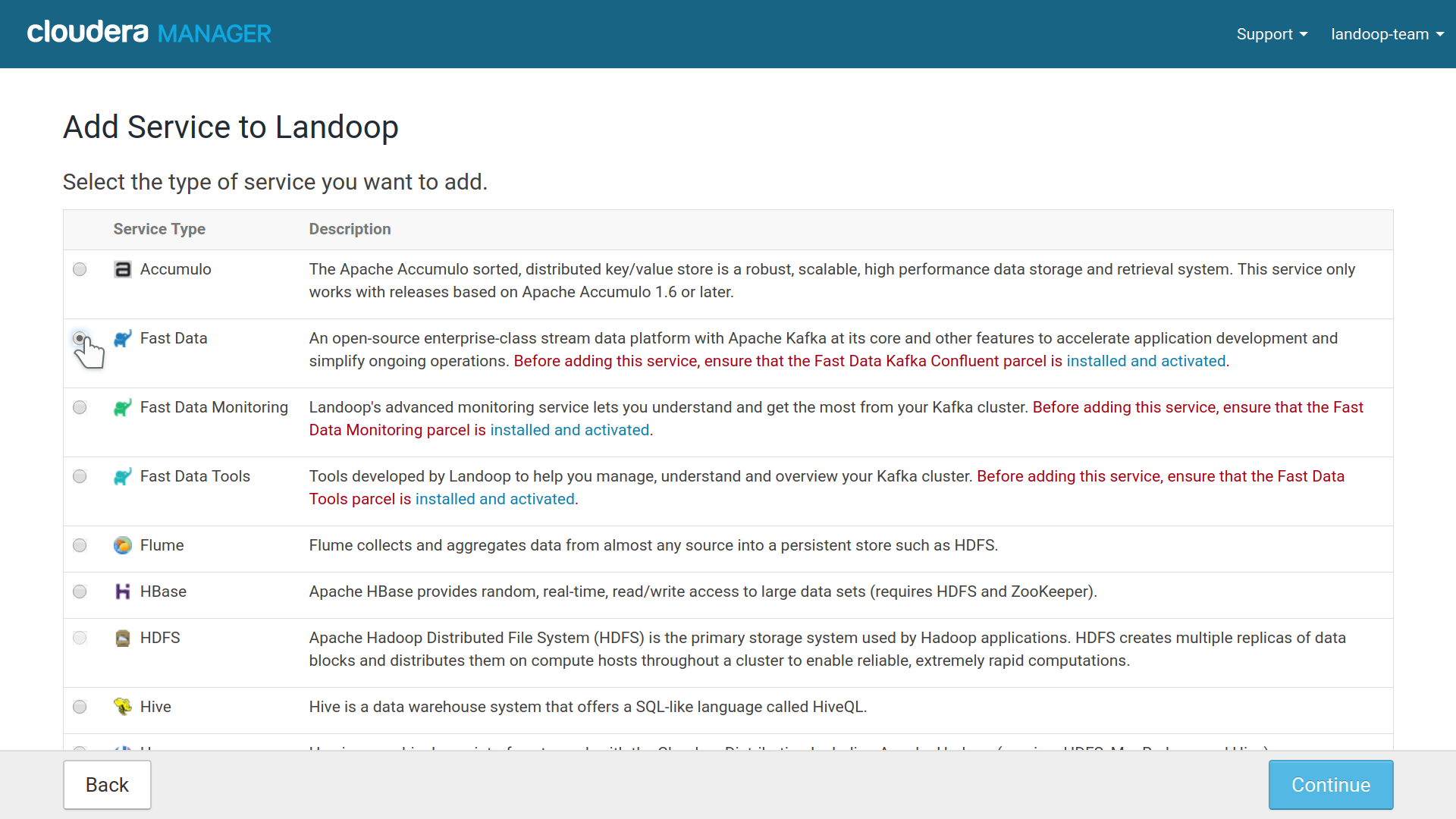
Fast Data service installation option in Cloudera Manager
In the second step you assign roles to your nodes. Usually you want many brokers for performance and availability, as well as some schema registry instances for availability. We recommend at least three brokers for production. REST proxies work independently and their number depends on your usage. If you use Landoop’s Kafka Topics UI (included in the Fast Data Tools CSD) you need one REST Proxy instance for serving as a backend. The number of connect distributed workers also depend on your performance and availability needs. If you use any of our other CSDs (Monitoring, Tools, Lenses) it is recommended to add one instance of Endpoint Exporter, so these CSDs can be configured automatically.
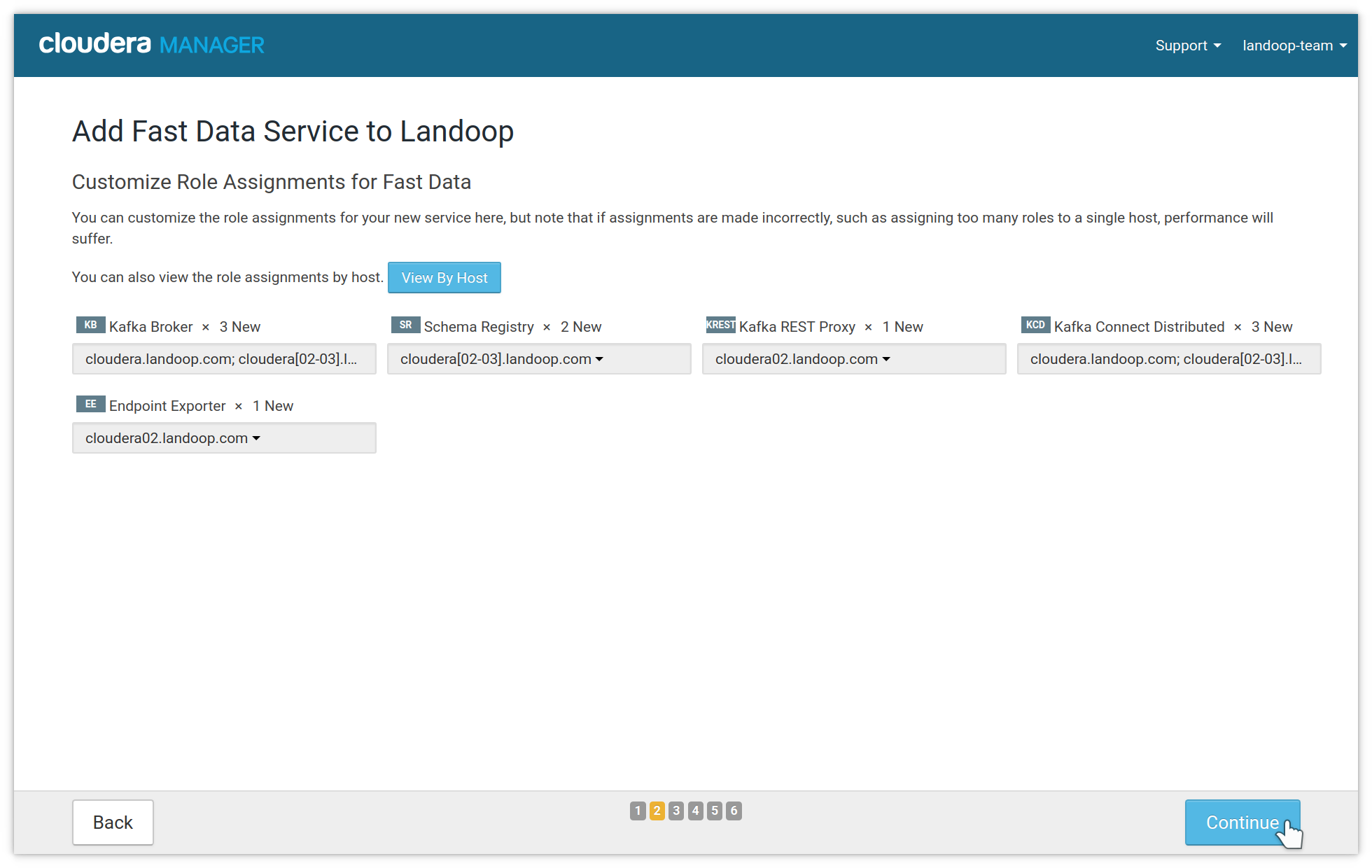
Fast Data role, instances assignment
If you have more than one Zookeeper services, an intermediary step will ask you to choose which Zookeeper the Kafka service should use.
The third step has some of the main settings for your Fast Data service. The default values, especially if this is your first setup of the CSD and you have at least 3 brokers set up, are usually good and you may continue without adjusting any option. Later you can use the CM service configuration tab to perform any adjustments you may need.
An option you may want to change and can’t be adjusted later, is the Zookeeper
Root. By default it is /fastdata but you may prefer something more
memorable for your developers, like /kafka.
If you have less than three brokers, you may want to adjust the replication factor for the Offset Commit, Connect Storage topics; the replication factor can’t be greater than the number of brokers.
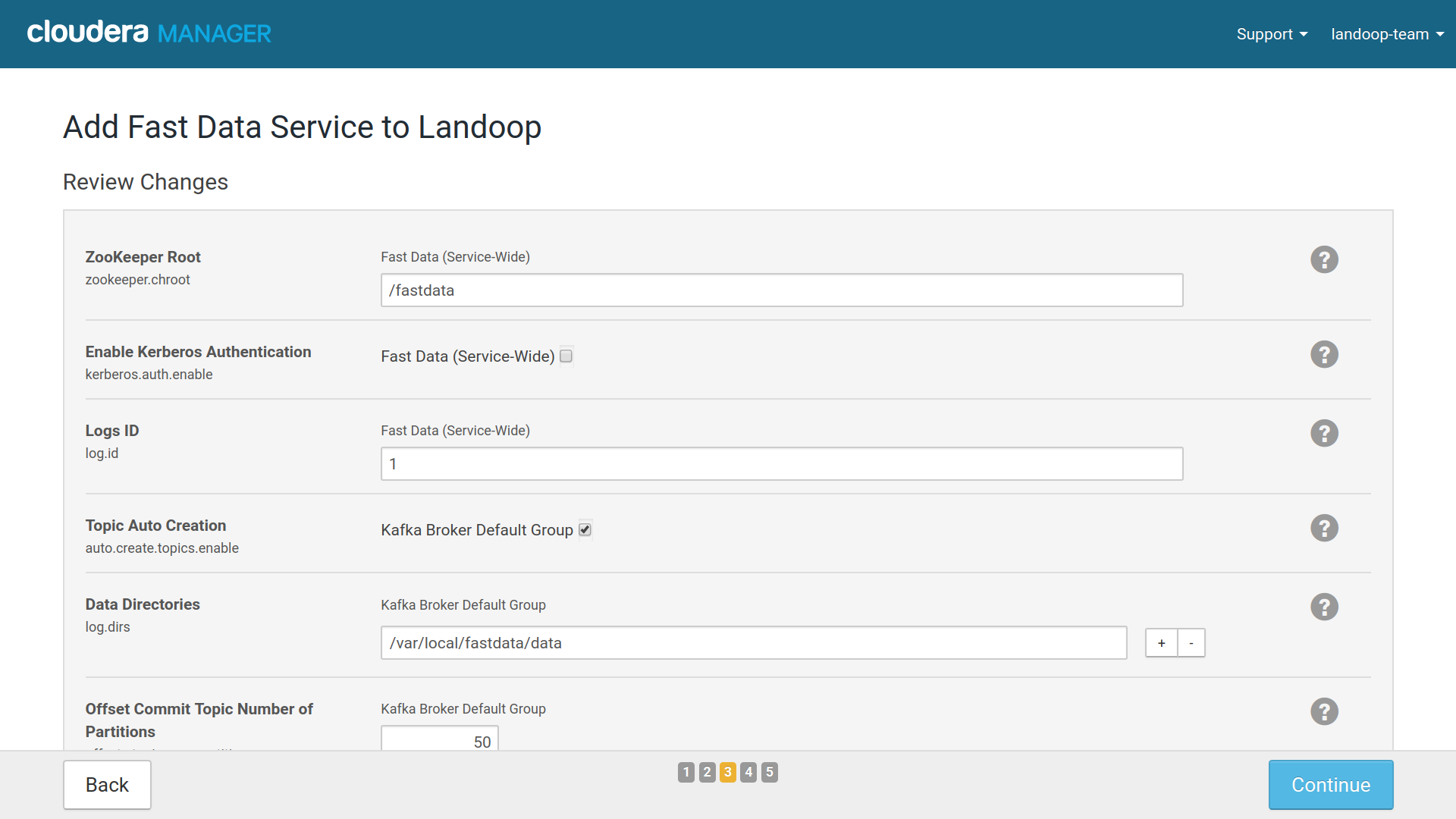
Cloudera Manager Install Wizard settings for Fast Data
Important
In order to avoid conflicts with previous Kafka installations we
set our brokers to store their data under a ZooKeeper znode
(default /fastdata). This is configurable in the setup
wizard. Make sure this znode doesn’t already exist from an older
installation of Kafka. Cloudera’s Kafka installation doesn’t use
a znode, it stores its data directly under /.
The last step will create the roles you assigned if possible. Usually it will not start them. You can press next and finish to complete the service creation.
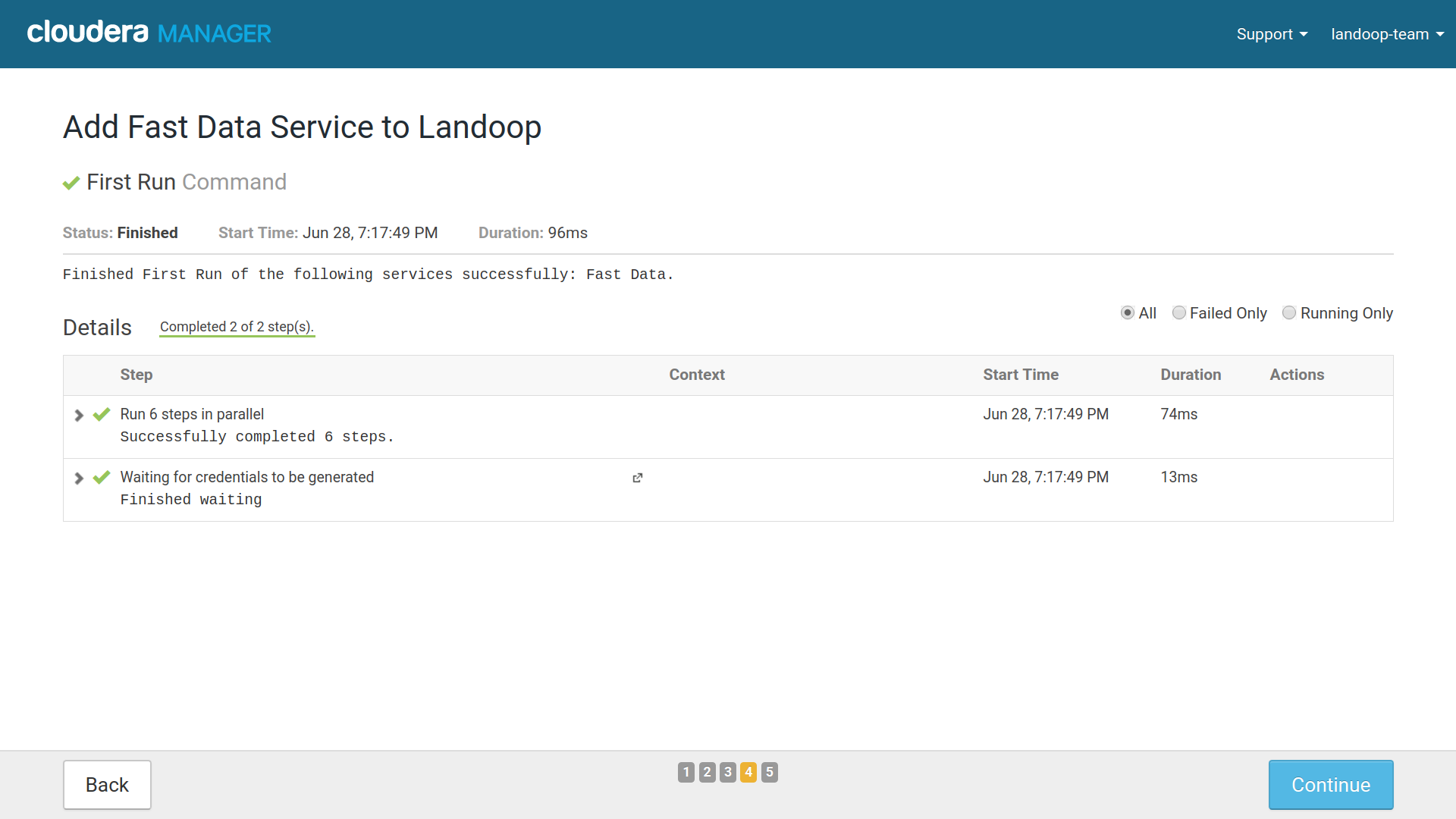
Fast Data Services Created Succesfully
You will find your new service at CM’s home page. If the manager warns about configuration issues, please check New Service Configuration Issues.

A new Fast Data service
In order to start the Fast Data service, it is recommended to first start the brokers and then the rest of the roles. Visit the service’s instances tab in CM, select the brokers and press start. Once everything is running, select the rest of the roles and press start.
Important
From time to time a role can fail to start. In that case it can be enough to try to start it again. The reasons a role can fail to start are multiple. For example starting at the same time all brokers or all connect workers, or starting the connect workers without enough brokers for the set replication factor of the configuration topics. If a role fails to start twice in a row, please check the stdout and other logs provided by Cloudera Manager.
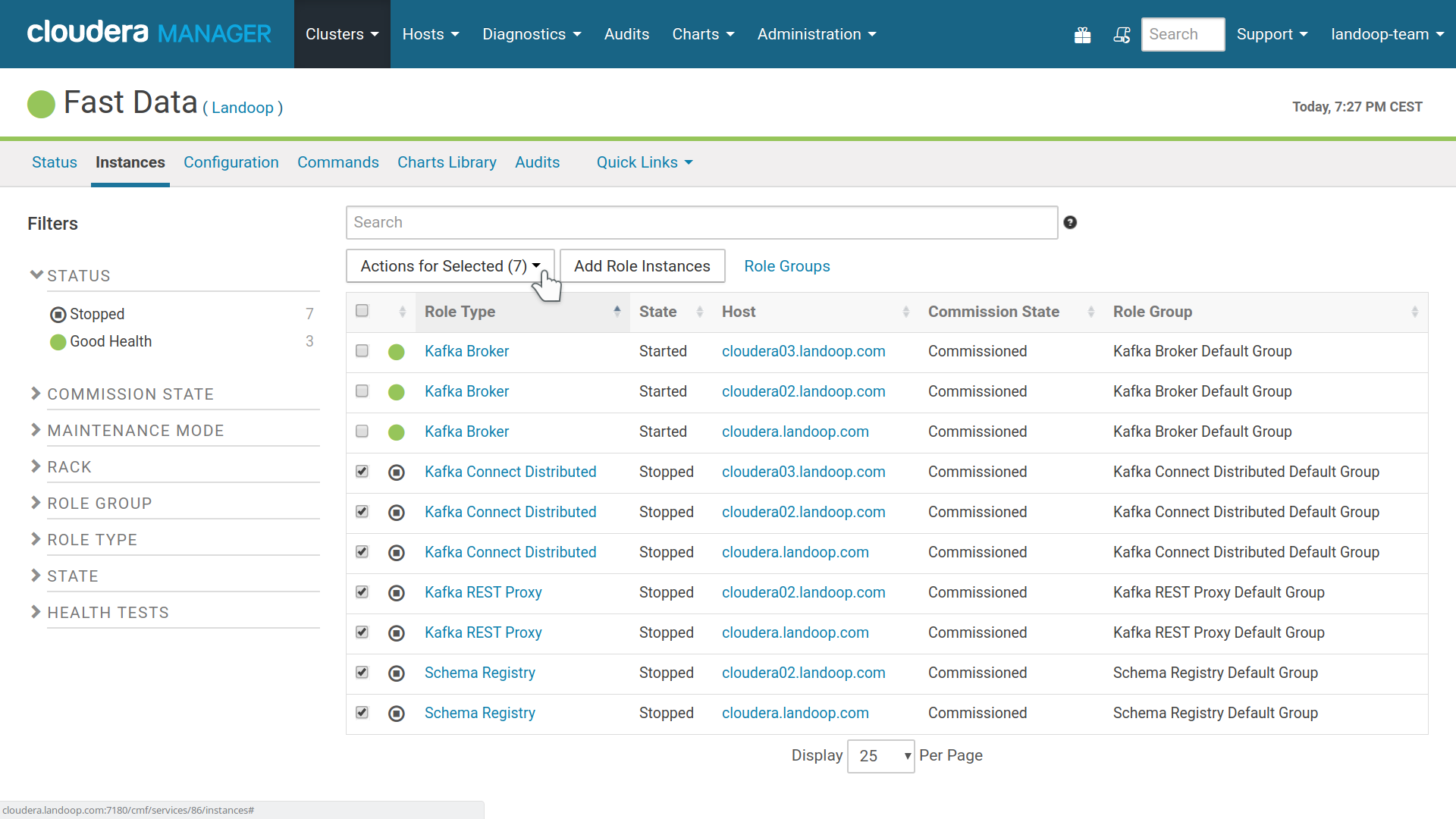
Start Fast Data roles, first the brokers, then the rest
From here you can continue to monitoring, Landoop UI’s (tools), adding connectors —we offer many and support custom ones— or to advanced installation and cleanup.
If you want to enable autoconfiguration of monitoring, please remember to enable
Export Metrics for Monitoring (fd.monitoring.prometheus). You will have
to restart your roles for the change to take effect. When you enable this
option, we augment the roles (e.g brokers) with a java agent that exports JMX
metrics to prometheus format. The addresses of these agents are exported by the
Endpoint Exporter role to zookeeper. The old method of manually setting up
external jmx exporters in the Monitoring CSD is still available.
Important
Various system topics are created with a default replication factor of 3. If your cluster has less than 3 brokers then this level of replication is impossible and some services, such as Connect, will fail to start. You may adjust the replication level for Connect’s topics (options Connect Config/Offset/Status Topic Replication Factor, available in settings and install wizard) to accomodate smaller setups and Connect will start once it is able to create its topics. Keep in mind that should you ever need to alter the replication factor, you will have to either create a new Connect cluster (change names of Connect’s topics) or manually adjust the replication factor as described in Kafka’s documentation
Note
Port 8083 which is Confluent’s default for Connect, is used by
CM‘s Report Manager. Thus we use port 8085 for Connect
Distributed; configurable via the settings page.
1.1.3.1. New Service Configuration Issues¶
Sometimes CM will not assign the minimum recommended memory for your new roles and report this as configuration issues.
Cloudera Manager warns about configuration issues
To fix this, visit Fast Data’s configuration page and increase the java heap size of each group of services. Depending on your usage, it might be a good idea to assign up to 5GB per broker with a minimum recommended of 1GB. Please note that you can go very far with just 1GB of RAM per broker, Kafka doesn’t need much RAM assigned to the brokers. Connect can be quite demanding on memory, depending on the connectors you use. Monitor your usage and adjust it accordingly. If you are on CDH 5.8 or better, CM will monitor your new services for out of memory errors. Our recommended minimum figures are 1GB for the Brokers, 512MB for Schema Registry and REST Proxy, 1GB for Connect workers.
The brokers will have their heap size enforced, ie they will try to take all the memory assigned to them and keep it. The rest of the roles will use memory as needed, adjusting the heap up (until the limit set) or down if resources can be freed.
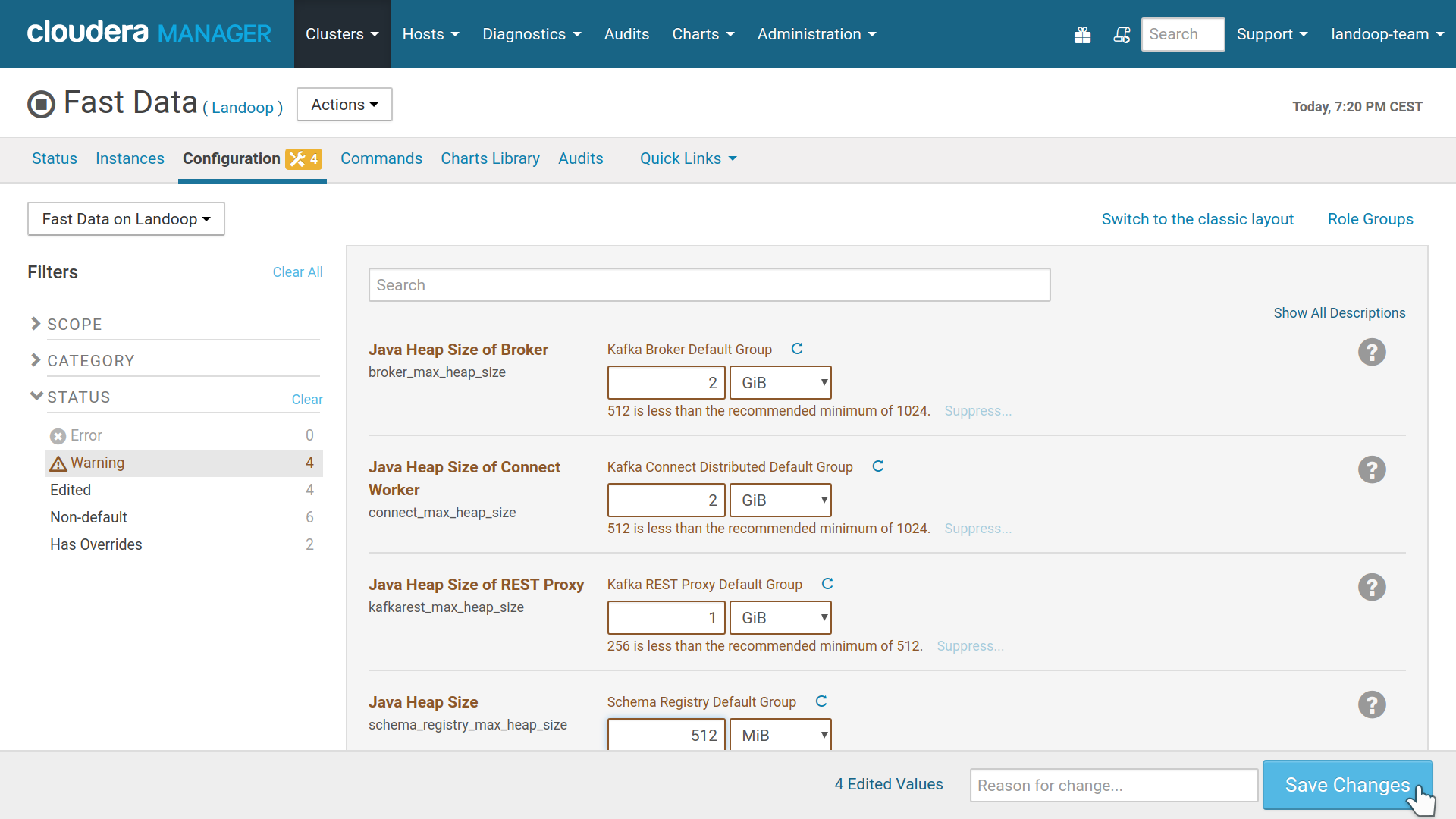
Resolving issues via increasing memory limits